Un asistente IA conectado a los datos de tu empresa (un sistema que responde con tu propia documentación, sin inventar, citando la fuente) dejó de ser ciencia ficción durante 2024 y 2025. La arquitectura se llama RAG (Retrieval Augmented Generation), está documentada desde 2020 y se implementa hoy en empresas medianas con plazos razonables. Esta nota explica qué es RAG en lenguaje de negocio, qué casos resuelve, cuándo no conviene todavía, y cómo evaluar si tu empresa está lista.
Del “ChatGPT general” al “ChatGPT con tu conocimiento”: qué cambió en 2025-2026
Durante 2023 y la primera mitad de 2024, la conversación corporativa sobre IA giró alrededor del modelo general. ChatGPT, Claude, Gemini: herramientas potentes pero que no saben nada de tu empresa. Un gerente preguntaba “¿cuál es nuestro procedimiento de devolución para clientes mayoristas?” y obtenía una respuesta plausible que no tenía nada que ver con lo que efectivamente decía el manual interno.
A partir de fines de 2024, el shift de conversación fue claro. Las preguntas ya no son “¿cómo me ayuda ChatGPT a redactar mejor?”. Son “¿cómo hago para que un asistente responda con la documentación de mi empresa?”. El término técnico que aglutina esa familia de soluciones es RAG, y el paper original que lo formalizó, Lewis et al., Meta AI, 2020, ya tiene cinco años. Salimos del laboratorio. Hoy es uso productivo en empresas.
Qué es un sistema RAG en lenguaje de negocio
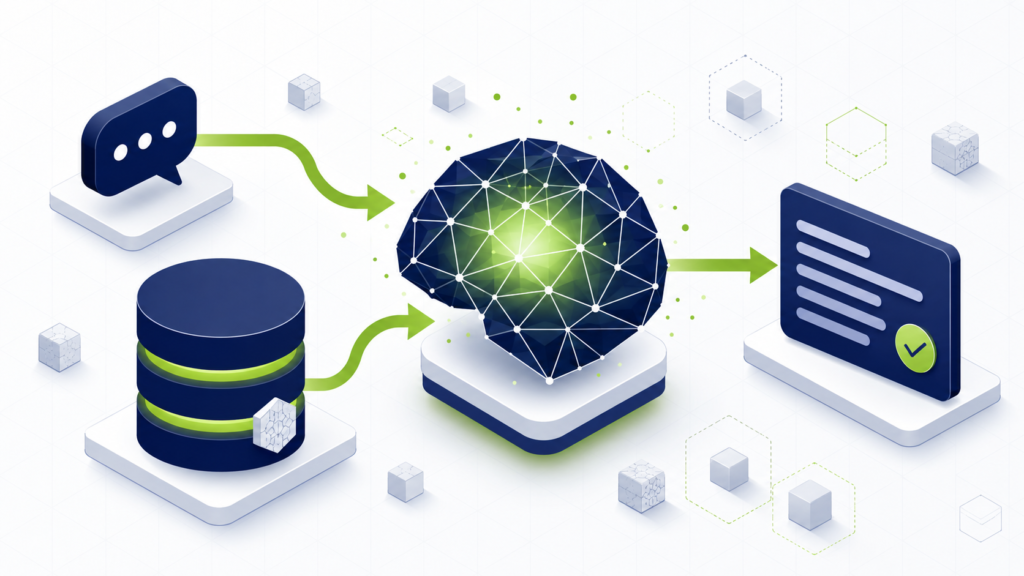
Sin tecnicismos: un asistente RAG es un sistema que:
- Tiene acceso a tu documentación interna: procedimientos, manuales, políticas, contratos, FAQs, intranets, drives, correos archivados. Tú decides qué documentos entran y cuáles no.
- Cuando alguien hace una pregunta, busca primero en esa documentación, no en internet ni en lo que aprendió un modelo general.
- Después usa IA generativa para armar la respuesta, pero anclándose siempre en lo que encontró. Si encontró tres párrafos relevantes, la respuesta los sintetiza.
- Cita la fuente de cada respuesta: el documento exacto, la sección, idealmente el párrafo. Así puedes verificar antes de confiar.
Cómo se diferencia de lo que ya conocías:
- Un chatbot tradicional (los de los sitios de bancos, por ejemplo) responde solo preguntas pre-programadas. No entiende preguntas nuevas, no improvisa. Se queda corto rápido.
- ChatGPT genérico entiende cualquier pregunta, pero no sabe nada específico de tu empresa. Va a inventar si no le dices lo contrario.
- Un asistente RAG combina las dos cosas: entiende preguntas nuevas como ChatGPT, pero responde únicamente con tu documentación, como un chatbot anclado a una base concreta.
Por qué RAG elimina las alucinaciones
Las alucinaciones (la IA inventando datos plausibles pero falsos) son el principal freno empresarial al uso de modelos generativos donde el costo de equivocarse es alto. RAG aborda el problema desde la arquitectura: el sistema solo arma respuestas basándose en información que está en tu documentación, dice “no encontré información sobre eso” cuando no encuentra, y cita la fuente de cada respuesta para que puedas verificarla. El modelo no entrena con tu data: la lee en el momento de cada pregunta, así que cuando actualizas un documento, las respuestas siguientes ya reflejan el cambio. Es el argumento que destraba la conversación con CEOs y CFOs escépticos del hype.
Los 4 componentes de un sistema RAG bien construido
Sin matemática ni jerga: Ingesta (cómo entran tus documentos al sistema: PDF, Word, intranets, drives), Base vectorial (la capa que representa cada fragmento de texto en forma comparable, permitiendo que el sistema encuentre lo relevante aunque la pregunta no use las palabras exactas del documento), Recuperación (busca los fragmentos que mejor responden cada pregunta específica) y Generación con citas (sintetiza la respuesta anclándose en los fragmentos encontrados, e incluye referencias al documento original para verificación). El usuario nunca interactúa con la base vectorial directamente; la calidad del sistema descansa en gran parte sobre las capas de recuperación y generación.
Tres casos de uso que ya están funcionando en empresas medianas
Soporte técnico interno
Problema: el equipo nuevo no encuentra respuestas en la documentación técnica. El senior pierde una hora por día contestando lo mismo. Cuando está ocupado, el equipo nuevo espera o adivina.
Después: el integrante nuevo pregunta al asistente (“¿procedimiento para configurar al cliente X?”), recibe respuesta en 5 segundos con cita al manual exacto. El senior queda libre. El conocimiento deja de depender de quién esté disponible.
Búsqueda en documentación legal y normativa
Problema: contratos firmados, regulaciones DGI, políticas internas. Encontrar la cláusula específica de un contrato lleva 30 minutos de revisar carpetas.
Después: pregunta natural (“¿qué dice nuestro contrato con el proveedor X sobre devoluciones?”), respuesta directa con cita al documento y número de cláusula. La consulta tarda segundos.
Asistentes de RRHH para políticas
Problema: el equipo de RRHH responde 30 a 50 veces por mes las mismas preguntas: licencias, beneficios, reembolsos. Consume tiempo de gente cara.
Después: los empleados consultan al asistente. Las respuestas son consistentes y citan la política exacta. RRHH se libera para tareas estratégicas y los empleados obtienen respuesta inmediata.
Cuándo RAG NO conviene (todavía)
Este es el punto donde se separa el contenido de catálogo del análisis honesto. RAG no es la respuesta universal. Lista de situaciones donde implementarlo hoy es prematuro o ineficiente:
- Cuando la documentación no existe o está muy desordenada. Basura entra → basura sale. Si tus procedimientos están en la cabeza de tres personas o en mails sin sistematizar, primero hay que ordenar, después RAG.
- Cuando el dolor real es de proceso, no de búsqueda de información. A veces el problema no es que la gente no encuentre la política, es que la política está mal o que el proceso es defectuoso. Un asistente no arregla un proceso roto, lo hace más buscable.
- Cuando el volumen de consultas es muy bajo. Si en tu empresa se consulta el manual cinco veces por mes, no hay caso financiero para implementar y mantener un asistente.
- Cuando los datos son extremadamente confidenciales y no hay infraestructura segura disponible. Hay arquitecturas que mantienen la data en tu propia infraestructura, sin que pase por servidores externos. Pero requieren más inversión y experiencia. Si el dato no puede salir bajo ningún concepto, esa restricción define la arquitectura.
Una nota honesta sobre la implementación entrega más valor que una promesa que no se sostiene. Si tu caso cae en alguna de estas cuatro situaciones, mejor saberlo antes de empezar.
Cómo saber si tu empresa está lista para implementar RAG
Cinco preguntas. Si respondes “sí” a tres o más, hay caso de uso real:
- ¿Tienes documentación interna estructurada (manuales, procedimientos, políticas) en algún formato razonablemente ordenado?
- ¿Hay una o dos personas que son “knowledge silos” y el resto los consulta constantemente?
- ¿El equipo nuevo tarda en encontrar información que ya existe en la empresa, escrita en algún lado?
- ¿Hay regulación, contratos o normativa donde encontrar la cláusula exacta lleva tiempo recurrentemente?
- ¿Existen consultas repetitivas que ocupan tiempo de gente cara y son respondibles desde documentación existente?
FAQ: dudas frecuentes antes de implementar un asistente RAG
¿Mis datos quedan en servidores de OpenAI o Google?
Depende de la arquitectura elegida. Las opciones van desde “todo en tu infraestructura, ningún dato sale” hasta “la consulta pasa por un proveedor externo bajo condiciones de uso comerciales”. La decisión se toma en función de la sensibilidad de tu documentación y de las normativas que apliquen a tu industria. No hay una respuesta única.
¿Hay que migrar toda la documentación a un formato especial?
No. Los sistemas RAG modernos ingestan PDF, Word, presentaciones, HTML de intranet, correos exportados, hojas de cálculo. Lo que sí ayuda (pero no es estrictamente obligatorio) es tener los documentos relativamente organizados. Documentación dispersa en 40 carpetas con nombres inconsistentes es ingestable, pero la calidad de las respuestas mejora si se ordena al menos un poco antes.
¿Cuánto tarda una implementación básica?
Un piloto operativo con un caso de uso acotado y un corpus documental razonable (cientos a pocos miles de documentos) entra en producción típicamente entre 4 y 10 semanas. Implementamos en semanas, no en meses porque cuando la documentación está en condiciones, el resto es ejecución acotada. La duración depende mucho más del estado de la documentación de origen que de la sofisticación del modelo elegido.
¿Sirve si tenemos documentación en varios idiomas o formatos?
Sí. Los modelos modernos manejan múltiples idiomas, incluyendo español rioplatense, sin problema. Los formatos mixtos (PDFs escaneados con OCR, presentaciones con imágenes, planillas) requieren más trabajo de ingesta, pero son abordables.
¿Qué pasa si la documentación se actualiza?
Los sistemas RAG bien diseñados mantienen la base sincronizada con las fuentes. Si cambias una política en el drive, las respuestas siguientes ya reflejan el cambio. Esto es una ventaja sobre cualquier sistema que dependa de “entrenar al modelo”: acá no hay entrenamiento, hay lectura en el momento.
Próximo paso
Si tu empresa tiene documentación interna que solo conocen 1-2 personas, y se pierde tiempo buscando información que ya existe, hay una solución concreta. No requiere que migres todo a la nube ni que reentrenes ningún modelo. BI aterrizado a tu operación también significa aplicar IA donde efectivamente resuelve un dolor, no donde queda bien en un PowerPoint.

Conversemos 30 minutos sobre tu caso específico. Sin pitch comercial, sin proyectos eternos. Si hay caso de uso real, te entregamos un plan operativo. Si no lo hay, te lo decimos honestamente.